Prologue
A year ago, I launched babiri’s open-source API. The project’s development halted shortly after as I acclimated to full-time work. The service proceeded to implode a few months after, left in radio silence until recently. With the advent of 2023, I’ve acquired the bandwidth to focus on developing a new suite of robust data tools. In particular, I’m happy to share what I’ve learned from industry to productionalize projects intersecting with my interests.
This post primarily covers the architecture for the new pipeline for daily data ingest pertaining to Pokémon Showdown high-ranked teams.
Alola, Statsugiri
babiri was the name of the project since its inception in early 2020. Unfortunately, the babiri.net domain has been lost to the trenches of domain name registrars. I attempted to register babiri.gg through Namecheap while releasing the babiri.net domain from GoDaddy prematurely. However, my Namecheap transaction was refunded since I missed their verification email. By the time I realized, both domains had been parked (presumably by bots). I adopted the Statsugiri domain name as a pun after the newly introduced sushi species in the Paldea region.
Pokémon Showdown Data Ingestion
The ingestion pipeline accomplishes an identical objective to the previous pipeline. Given a format (eg. gen9ou), the highest-ranked players on the Pokémon Showdown ladder are retrieved. The most recent replay for the requested format is parsed for team information through regex. If a player has no public replays available (eg. private replays), the next highest-ranked player is used as a datapoint. This is repeated until 100 teams have been parsed.
Infrastructure Autopsy
A few issues undermined the feasibility and maintainability of the first iteration.
Tedious Deployments
I leveraged AWS Lambda for the pipeline and EC2 for server hosting. While Lambda abstracted some infrastructure work, there was still a fair share of operations work to manually associate resources such as EventBridge triggers. It was particularly unscalable for redeploying Lambdas as I’d have to build the images locally and upload them to ECR via CLI for each Lambda. EventBridge was also an issue if I wanted to include more formats. Server deployment was unideal since I had to manage SSL and manually build images to deploy as well.
Lack of Monitoring
There was little monitoring to notify when the pipeline or server failed. The only available mechanism was to check the server to see if new data had been published for the day.
Singular Point-of-Failure
Deploying the server on a single manually provisioned micro EC2 instance meant the service would be down if anything happened. To achieve redundancy, I’d have to manually provision multiple EC2 instances which is a time investment.
Accessibility
Accessing the API was possible through making requests, such as through CURL. For non-technical audiences, the easiest method of making a request is through the browser. Should you go this path, the result is a massive JSON object bordering unreadable. I needed a middle-ground for making the data accessible for anyone in the community.
Infrastructure Changes
To address previous shortcomings, I adopted AWS CDK into the workflow. Leveraging infrastructure as code (IaC) allows for deterministic deployments since it synthesizes the CloudFormation template for you. Manual configuration is greatly reduced since CDK handles creating and updating resources for every deployment. It also provides the added benefit of modularizing my application into stacks for more granular deployments. This concept extends to creating different stacks for different environments (eg. prod vs dev) and to provision dashboards and alarms. Though there are other IaC frameworks such as Terraform, I opted for CDK for its familiarity and simple interface. Vendor lock-in isn’t a concern given the scale of the project.
I aimed to deliver the data within the first few weeks of January, preferably before San Diego Regionals. Given the timeline of 2-3 weeks, delivering a full-stack application was out of the picture. Instead, I opted to deliver the information through Twitter via their API. This was intended to be a lightweight, “belts-n-suspenders” solution to serve the community while I focus on the site. As a result, @OrderUpTeamsBot was created.
PS Ingestion Pipeline V2
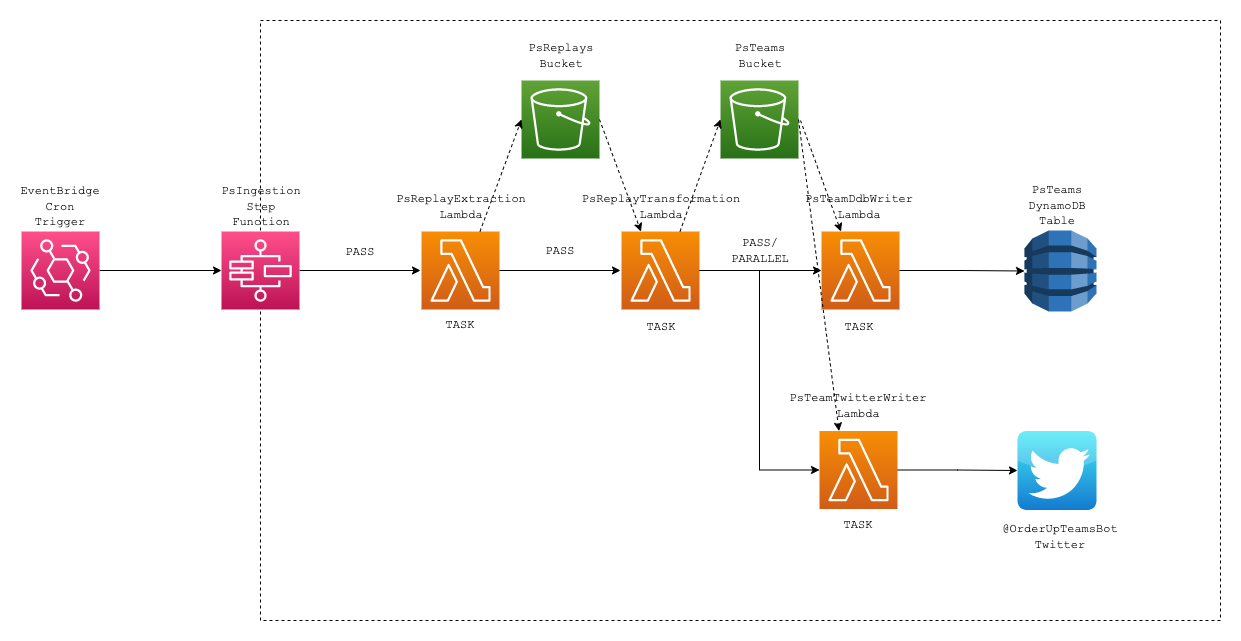
The high-level architecture features a few notable design choices. You can find a full-size image of the high-level design here.
State Machines
The ingestion pipeline is orchestrated with AWS Step Functions. Replay retrieval, team parsing, and writing are contained within their own Lambdas. Step Functions is capable of running branches in parallel, allowing for writes across multiple destinations. Decoupling data flow from business logic helps reduce the invocation duration compared to a single Lambda configuration instead. I initially considered invocating each Lambda with SNS to chain invocations with pub / sub, but couldn’t avoid the SNS calls being synchronous. Though it’s likely possible to make the calls asynchronous, Step Functions brought other advantages.
Error handling and retries are important as the system may not know the data Pokémon Showdown provides. At the Lambda level, most issues were concerns with dependencies on some quirks of the Pokémon Showdown server. Most notably, the requests to retrieve player replays experienced higher variance in latency. I suspect it’s due to some players having a large number of replays, but retrieving a single page didn’t improve the response time through my impromptu benchmarking. The latency spiked upwards of 30 seconds in the worst scenarios. Iterating through a minimum of 100 replays meant the latency was a potential risk to Lambda’s 15 minute execution limit. Another theory was the Pokémon Showdown server suffered from intermittent cold starts resulting in slowdowns. I added retries with backoff in an attempt to mitigiate the issue, but to no avail. I valued the pipeline running end-to-end reliably over correct data. I wanted the pipeline to retrieve a variety of teams while minimizing manual intervention. Weighing the trade-offs, I opted to skip to the next highest-ranked player if the replay request times out which was a reasonable compromise.
Step Functions provides granular retries which is particularly useful where the writers fail. In a monolithic Lambda, the Lambda can only execute the writers sequentially. The sources may be out of sync with each other if the DynamoDB writer succeeds but the Twitter writer fails. Step Functions allows you to restart failed states so you can retry without duplicating data from previous successful states.
Another interesting issue involved how Pokémon Showdown validates usernames when searching for replays. From my investigation, the server only accepts alphanumeric characters. Non-alphanumeric characters such as underscores and spaces are ignored. Usernames are also case-insensitive. For example, Cool user, cooluser, cool_user, and とてもcooluser all register as the same username. It is also possible for a user to register on ladder as a different username than appears in replays (eg. upper-case) since the server does not “correct” the username. Despite having to relearn regex every time I rewrite the project, I followed a regex pattern similar to this Stack Overflow post. I foresee more regex in the project’s future, so this likely won’t be the last time I encounter it.
Payload Size Issues
To pass data between Lambdas, I intended to serialize the internal classes into JSON dictionaries. However, I didn’t account for Step Functions’s limited payload size when testing in the development environment. I would normally consider Pickle for serialization, but the Lambdas don’t have knowledge of other Lambdas’s internal classes. I followed a design pattern AWS acknowledges where large payloads are stored in intermediary S3 buckets to be read at the next state. Each Lambda’s payload is comprised of the bucket name and key where the previous state’s data was stored. Since I already serialized the data into JSON dictionaries for my initial design, I kept them the same out of laziness.
CI/CD Pipeline
The project uses Github Actions for its CI / CD pipeline just like its predecessor. Lambda images are deployed through ECR, where the repos are manually provisioned. I configured Github Actions to automatically build and push images on every merged pull request through AWS Actions. Through development environment testing, I ran into issues where uploading an image tagged latest would reassign the image tag, but the Lambda wouldn’t redeploy with the new changes. I eventually stumbled upon some discourse in this Stack Overflow post explaining the root cause. To mitigiate the issue, I tagged new images build from Github Actions with a truncated commit hash and specified the tag during CDK deployments. While the workflow has served well, I’m investigating if Github Actions can build new images only if there’s new changes to the image to minimize the number of images in ECR (and thereby, reducing costs).
Credential Handling
I handled credentials for the Twitter API through Secrets Manager, which was manually provisioned for development and production environments. The credentials would be read from Secrets Manager and passed into the writer Lambda through environment variables. CDK streamlined the deployments between development and production greatly for this use-case.
Current State
Unfortunately, Twitter announced they would begin charging for their API services. The costs made it difficult for a single developer to justify continuing work on the Twitterbot. Though short-lived, the Twitterbot generated positive feedback and saw an average of a few hundred views per day. Regardless of Twitter’s future policies, it is the right call to invest engineering effort into the core application for the future.
Conclusion
Treading Overengineering
I built the first version of babiri in 6 weeks, which is a short time to deliver in hindsight. Though the first version was delivered rapidly, I was unsatisfied with the maintenance required to keep it running. I approach projects aiming to build robust and maintainable software as it’s difficult to reduce operations work while balancing a full-time position. I’ve also gained an appreciation for learning new technologies and design patterns through tackling new projects. Exploring new ideas promotes growth as an engineer and person, which are things I greatly value. After all, I have the agency to refactor less than ideal features as long as time permits.
Special Thanks
Some shoutouts to a few individuals.
- Tony Chen: for providing design review feedback.
- Everyone I talked to at Orlando Regionals. Plentiful ideas, just need to find the time to execute on them.
I recently also started a Ko-Fi to help with hosting costs and content creation (such as the post you’re reading!). I’m hoping to write more as development continues.