Prologue
Upon finishing the PS ingestion pipeline, next on the list was to implement a back-end as a means to serve the team data. Thus, this post discusses design considerations for the aforementioned PsTeamsService. You can try out the API here, complete with usage documentation.
Serverless Simplicity
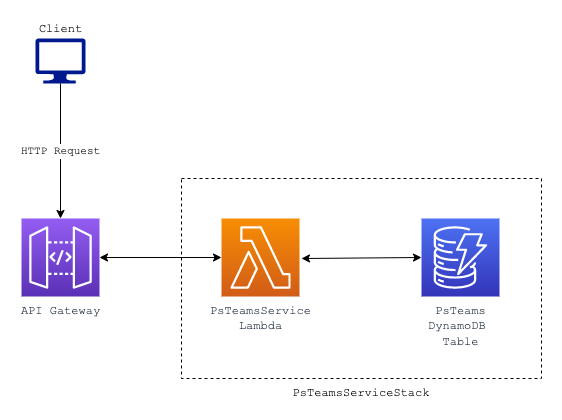
You can find a full-size image of the high-level design here.
After some discussion, I opted for AWS Lambda and API Gateway to handle requests to the DynamoDB storage. Consideration was made for hosting the service on ECS Fargate, but the incurred additional cost and maintenance for compute didn’t feel justified. Fewer resources also means fewer points of failure.
I ended up moving API Gateway to a separate CDK stack since it can be re-used to integrate with other services in the future. Deploying the stack is a time-consuming process since it also creates resources for associating the external domain. In particular, certificate validation via DNS takes time as does DNS propagation when associating a CNAME record with your external domain. The intended workflow is to deploy your service stack for console testing. When developers wish to test end-to-end, they can deploy the API Gateway stack after confirming their individual services are working as intended.
Database Access Patterns
For the current iteration, there were two primary use-cases.
- Retrieving teams from a date (ie. “snapshot date”)
- Filtering teams by certain Pokémon
- eg. return all teams with Arcanine and Palafin
I structured the API endpoints so clients were required to provide both a format and date. This allowed me to create a composite key to act as the sort key (eg. gen9vgc2023regulationc#2023-04-11). In addition, a global secondary index (GSI) was added to the composite key for querying. Thus, the first use-case is fulfilled through this schema design.
The second use-case is a bit more interesting in how it can be tackled. Let’s take a look at two options.
Multiple Record Writes
Credits to my coworker, Daniel, for suggesting the design.
To efficiently filter by a Pokémon, the DynamoDB data producer can write each individual Pokémon per team as the sort key as its own record under the same primary key. The sort key can be a flexible field for serving either the Pokémon on the team or other metadata (eg. DynamoDB item type).
| primary_key | sort_key (gsi) |
| ----------- | -------------- |
| 1000 | team |
| 1000 | amoonguss |
| 1000 | arcanine |
| 1000 | flutter mane |
| 1000 | great tusk |
| 1000 | iron bundle |
| 1000 | ting-lu |
Putting a GSI on the sort key lets DynamoDB do the heavy lifting for you. The sort key can be a composite key with the snapshot date (eg. amoonguss#2023-04-14) to make queries easier.
Unfortunately, the design falls short when filtering for multiple Pokémon. Every Pokémon the client filters for is an additional query. In addition, every team requires up to 6 additional writes for each Pokémon in the team.1 The multiple item writes is a clever design for efficient reads when you have a set of items as an alternative to forcing a GSI onto the column.
Client-Side Filtering
Client-side filtering was the accepted choice given the payload size. With each query being relatively small (100 items at most, each item less than 400 bytes), client-side filtering isn’t too costly from a performance standpoint. Even when filtering for multiple Pokémon, the performance has a comparable latency2 to filtering for a single Pokémon.3
| team_id(pk) | composite (gsi+sk) | pkmn_team |
| ----------- | -------------------- | ------------------------------ |
| 1000 | vgcformat#2023-04-14 | ["amoonguss", "arcanine", ...] |
| 1001 | vgcformat#2023-04-14 | ["chi-yu", "great tusk", ...] |
| 1002 | vgcformat#2023-04-15 | ["chien-pao", "dondozo", ...] |
Building on Change with Github Actions
Previously, Github Actions would build and push Docker images to Elastic Container Registry (ECR) from every service when a pull request was merged. As a result, every merge cluttered the ECR repos with superfluous images, making it difficult to discern images during deployment. Additional costs were also incurring with every commit.
I previously investigated solving this with Github Actions’s paths filter. The paths filter can detect changes and run workflows based on file changes, such as building the ingestion pipeline image only when changes were made to the directory. Simple solution, right?
Unfortunately, I encountered many hurdles with this configuration. In fact, this Stack Overflow post seems to corroborate my experience where it isn’t possible at the workflow level. Coincidentally, I stumbled upon this post on integrating the changed-files action, which is the same action suggested in the Stack Overflow post. My workflow is similar, though it checks only for Python file changes within each directory. The production code doesn’t depend on other file types (eg. .txt, .json) outside of tests, though that may change in the future. After a few dummy commits to test the workflow, I was happy to confirm it was Spring Cleaning for ECR.
Conclusion
Though a relatively simple service, migrating to AWS / CDK has been a massive quality-of-life improvement for deployments and monitoring (ie. alarms and dashboards). With a backend deployed to prod, all that’s left for an official launch is the UI. If you enjoyed this write-up, please consider supporting the project through Ko-Fi or Github Sponsors.
Pokémon Showdown enforces a minimum of 4 Pokémon per team, so every record has, at minimum, an additional 4 writes. That being said, most teams will have 6 Pokémon for competitive advantage. ↩︎
Given it’s a personal project, my tolerance for “acceptable” is anything less than a second. Certainly an unambitious bar, but an unnecessary worry until customers see a noticeable difference. Refer to my caching write-up for more thoughts. ↩︎
Brief curl benchmarking showed about 130-150ms for both queries. Again, these seem like decent numbers until they aren’t. ↩︎